[持续更新中] Last Update: 2023/3/11
摘要
联邦学习是一种新兴的机器学习技术,它能够在保护隐私数据的同时,利用本地数据训练全局模型,降低通信开销和支持分布式设备,同时提高模型的精度和泛化性能。本文将介绍联邦学习的概念、常用算法、优缺点和应用场景。
概念
联邦学习是一种分布式机器学习技术,它将分布式的本地数据集合在一起,利用本地数据训练全局模型,同时保护每个设备的数据隐私。在联邦学习中,各个设备本地进行模型训练,然后将本地模型参数上传至中心服务器进行全局模型聚合。由于本地数据不离开设备,联邦学习能够保护隐私数据,并且减少了通信开销,同时提高了模型的泛化性能。
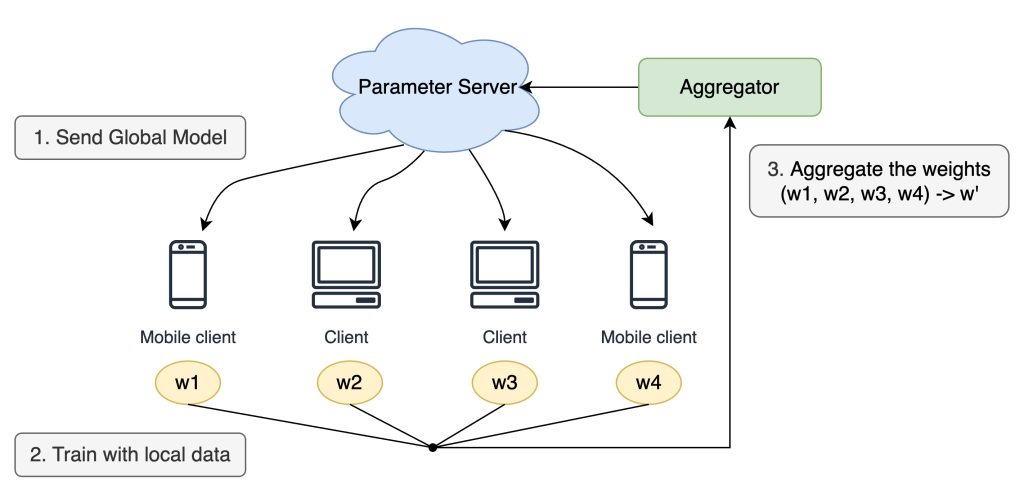
常用的联邦学习算法
聚合算法
FedAvg
FedAvg算法是一种联邦学习算法,它通过在设备本地进行模型训练,将本地模型参数上传至服务器进行全局模型聚合,避免了上传原始数据的风险,并且减少了通信开销。FedAvg算法是目前应用最广泛的联邦学习算法之一。
详细解读看这里:
FedProx
FedProx算法是一种改进的FedAvg算法,它引入了正则化项来平衡本地模型和全局模型之间的权重。FedProx算法可以提高全局模型的准确性和泛化性能,并且能够更好地处理数据不平衡和设备异构性问题。
FedOpt
FedOpt算法是一种针对联邦学习中的优化问题提出的算法。该算法采用了一种递归的方式进行模型训练,并且引入了一些新的优化技术,如动量和自适应学习率,以提高模型的训练效果和收敛速度。
攻击算法
数据污染攻击(Data Poisoning Attack)
这是一种针对参与者本地数据集进行篡改或注入恶意样本来影响全局模型训练效果的攻击方法。
模型替换攻击(Model Replacement Attack)
这是一种针对参与者本地模型参数进行替换或修改来影响全局模型训练效果或泄露其他参与者信息的攻击方法。
梯度泄露攻击(Gradient Leakage Attack)
这是一种利用服务器返回给参与者的梯度信息来推断其他参与者数据特征或标签信息的攻击方法。
防御算法
梯度裁剪(Gradient Clipping)
这是一种简单有效的防御方法,它通过限制每个参与者提交给服务器的梯度范数来减少异常或恶意更新的影响。
Krum
Krum算法的基本思想是,在多个模型的预测结果中,选择一个最具代表性的结果作为最终预测结果。这个最具代表性的结果应该具有较高的预测准确度,并且和其他模型的预测结果差异较大,这样可以降低集成模型的误差。
Bulyan
Bulyan是基于Krum改进的算法,在Krum的基础上增加了Trimmed Mean。
联邦学习的优缺点
优点
(1)保护数据隐私:联邦学习能够在不共享原始数据的情况下,利用本地数据进行模型训练,保护了数据隐私。
(2)降低通信开销:联邦学习能够在设备本地进行模型训练,减少了上传数据的通信开销。
(3)支持分布式设备:联邦学习能够支持分布式设备,每个设备可以在本地进行模型训练,从而降低了中心服务器的负担,提高了算法的扩展性和适用性。
(4)提高模型的精度和泛化性能:联邦学习能够利用更多的本地数据进行模型训练,从而提高模型的精度和泛化性能。
缺点
(1)数据不平衡问题:由于设备本地数据集的不同,可能导致每个设备的训练模型的质量和精度存在差异,从而影响全局模型的准确性和泛化性能。
(2)设备异构性问题:由于不同的设备硬件配置和软件环境不同,可能会导致本地模型参数的差异,从而影响全局模型的收敛性能。
(3)隐私泄露问题:虽然联邦学习能够保护隐私数据,但是仍然存在一些潜在的隐私泄露问题,如全局模型的参数可能会暴露一些隐私信息。
应用场景
联邦学习技术已经被广泛应用于医疗健康、金融、智能交通等领域。其中,医疗健康领域是联邦学习应用最为广泛的领域之一,例如,联邦学习技术可以应用于医学图像分析、医疗诊断和个性化治疗等领域。此外,联邦学习技术还可以应用于金融风险评估、智能交通路况预测等领域。
论文推荐(持续更新)
联邦学习大综述:Advances and Open Problems in Federated Learning
FedAvg: Communication-Efficient Learning of Deep Networks from Decentralized Data
Krum:Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent
Bulyan: A Little Is Enough: Circumventing Defenses For Distributed Learning

评论 (0)